More Context, Worse Answers
Long context windows are useful, but they do not guarantee better reasoning. Sometimes AI coding sessions fail because they contain too much stale information.
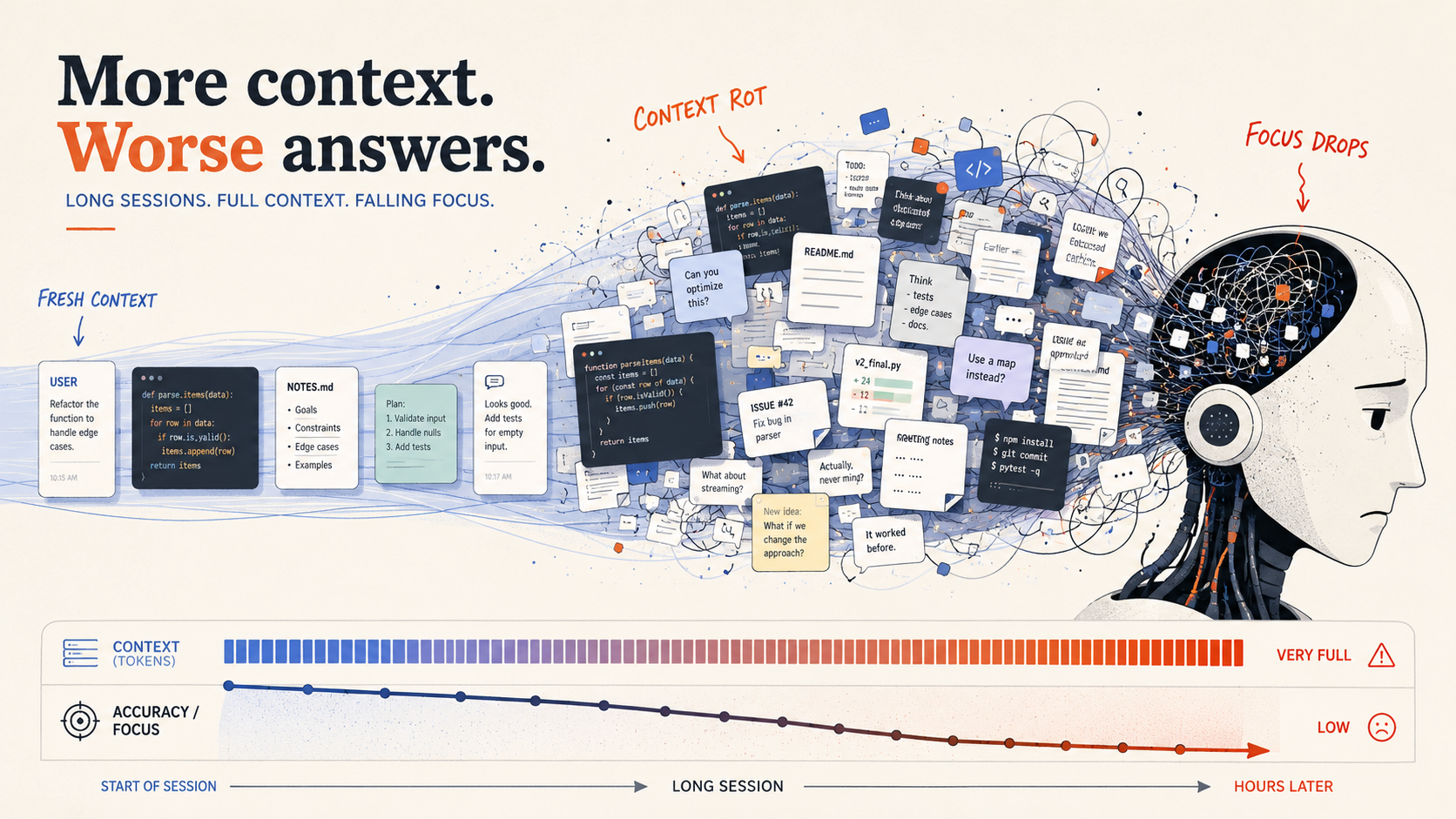
An AI coding session often starts well. The agent reads the relevant files, understands the request, and makes a reasonable plan.
Half an hour later, it edits a function that no longer exists.
The agent saw the old version near the beginning of the conversation. Since then, the file changed, two attempted fixes failed, and the user clarified the requirement. All of those states remain in the transcript. The model now has plenty of information, but some of it describes a project that no longer exists.
This is often called context rot: a session becomes less reliable as useful facts get mixed with stale or irrelevant ones.
A large context window is capacity, not understanding
A context window tells you how much input a model can accept. It does not promise that the model will retrieve every relevant detail or weigh every part of the input correctly.
That distinction matters in coding work because the context changes while the agent is using it. A long session may contain:
- file contents from before an edit;
- failed approaches that should not be tried again;
- instructions later replaced by a clarification;
- test output from an earlier version of the code.
None of this is necessarily useless. A failed attempt can explain why the next approach is better. Old test output can reveal when a regression appeared. The problem is that historical information and current state arrive in the same stream.
Suppose an agent first decides that a bug belongs in the API layer. It reads three API files and proposes a fix. A later test proves that the bug is in a React component instead. The earlier analysis still occupies much more space than the short correction. If the model gives too much weight to that analysis, it may continue reasoning from a premise that has already been disproved.
The session is not missing context. It has failed to distinguish evidence from history.
Long-context benchmarks show the limit
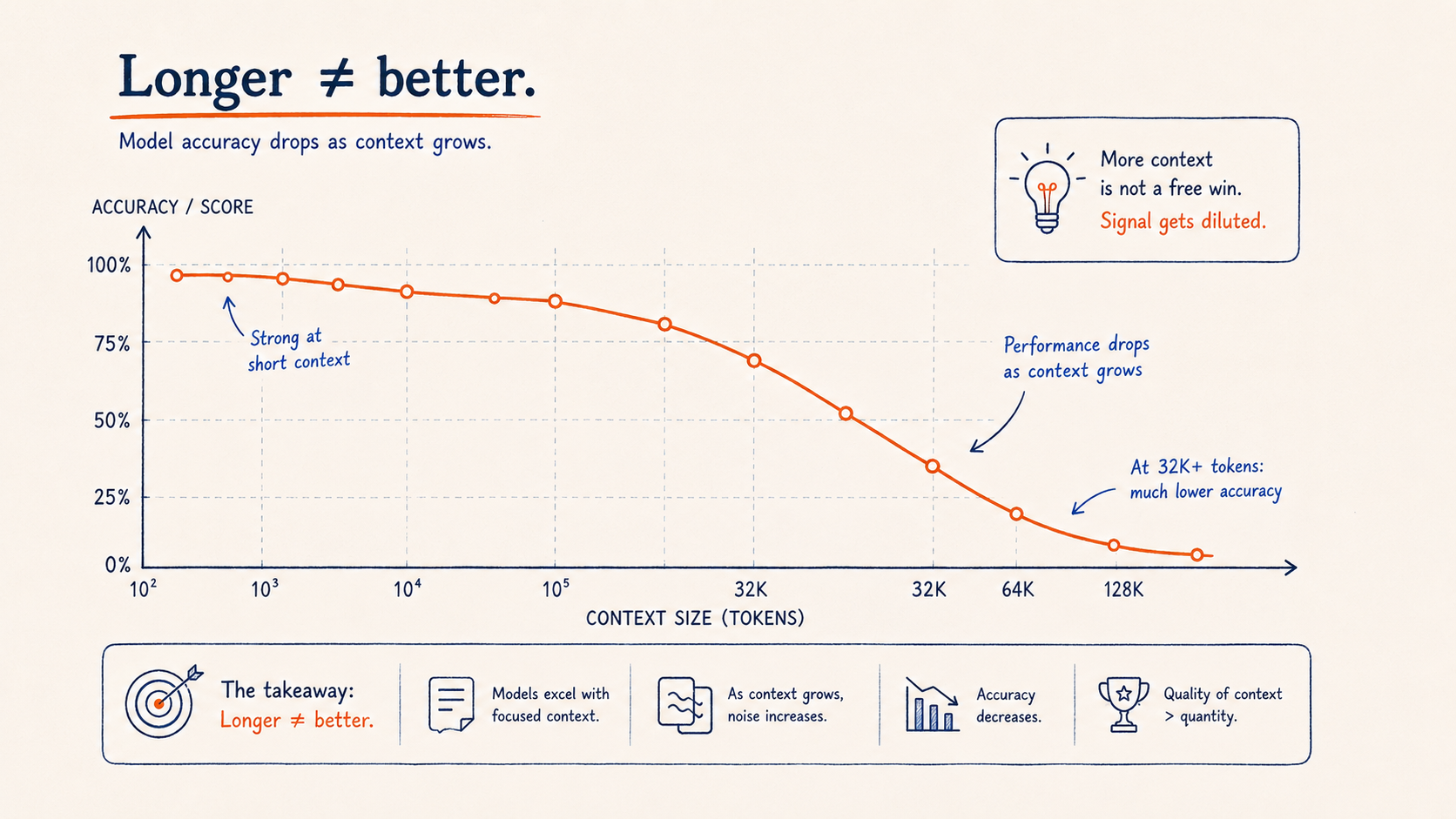
Benchmarks cannot reproduce a messy afternoon in a real repository, but they do show that advertised context length and reliable use of context are different things.
Chroma's Context Rot study tested models on controlled tasks while increasing the amount of input around the relevant information. Performance generally became less reliable as the context grew. The decline varied by model and task, which is important: there is no single token count at which every model suddenly stops working.
NoLiMa tests a harder form of retrieval in which the question and the relevant passage do not share obvious wording. In its published results, GPT-4o fell from a 99.3% short-context baseline to 69.7% at 32K tokens. Ten evaluated models dropped below half of their short-context baseline at that length.
Those numbers describe a benchmark, not a universal law of coding agents. Still, the failure resembles what developers see in practice. Finding the right fact becomes harder when it is surrounded by more competing material, especially when the relevant fact must be inferred rather than matched by a keyword.
Tools built around long-context models account for this problem in their design. Anthropic documents that previous turns accumulate in the context as a conversation grows, and Claude Code provides /clear to start a session with fresh history. Google's LangExtract processes large documents with chunking and repeated passes over smaller contexts because multi-fact recall can decline across very long inputs.
The useful lesson is narrower than “long context is bad.” Long context is valuable when the extra material is relevant. It becomes a liability when the model must separate the current task from several obsolete versions of it.
Why coding sessions are vulnerable
Most documents stay fixed while a model analyzes them. A codebase under active development does not.
During one task, files are edited, tests change the diagnosis, and constraints surface. An agent may read a file, modify it, and later reason from the earlier copy embedded in the conversation. Terminal output has the same problem: a failure from twenty minutes ago can remain visible after the underlying issue has been fixed.
Humans deal with changing state by rebuilding a mental model. We reopen the file, check the current diff, and write down what has already been ruled out. Coding agents benefit from the same habits.

The goal is not to keep the context artificially tiny. It is to make the current state easy to identify.
Reset the task, not just the conversation
Starting a new session helps only if the new prompt contains a better description of the work. Copying the entire old conversation into a fresh chat recreates the same problem.
When a session begins to drift, make a short handoff with five pieces of information:
Goal:
Fix the duplicate checkout request.
Current evidence:
The API receives two calls from CheckoutButton.tsx.
Relevant files:
components/CheckoutButton.tsx
tests/checkout.spec.ts
Decisions:
Keep the API endpoint unchanged.
Do not retry:
The debounce approach; it hides the duplicate event and broke keyboard input.
Next check:
Reproduce the double submission in the component test.This format separates current evidence from discarded ideas. It also gives the next session a verifiable first step instead of asking it to reconstruct the entire investigation.
Several smaller habits help before a full reset is necessary:
- Ask the agent to reread a file before changing it.
- Check the current diff after a long sequence of edits.
- Keep one session focused on one outcome.
- Record decisions when they replace earlier instructions.
- Treat repeated corrections as a sign that the working model of the task is wrong.
These habits are useful even when the context window is nowhere near its limit. Token capacity is only one issue; stale state can appear after a handful of turns.
Context should describe the next decision
The best context is not always the shortest, and it is rarely the largest available dump of information. It is the evidence needed for the next decision, with the current state clearly separated from the path taken to reach it.
If an agent starts repeating a rejected fix or citing code that has changed, another paragraph of instructions may make the session worse. Stop, inspect the repository as it exists now, and write a compact handoff.
You are not throwing away useful work. You are preserving its conclusions without preserving every wrong turn.