Why Netflix Took 7 Years To Migrate To AWS
Netflix's AWS migration was not a simple lift and shift. It was a full rebuild of how the company designed, deployed, scaled, and recovered software.
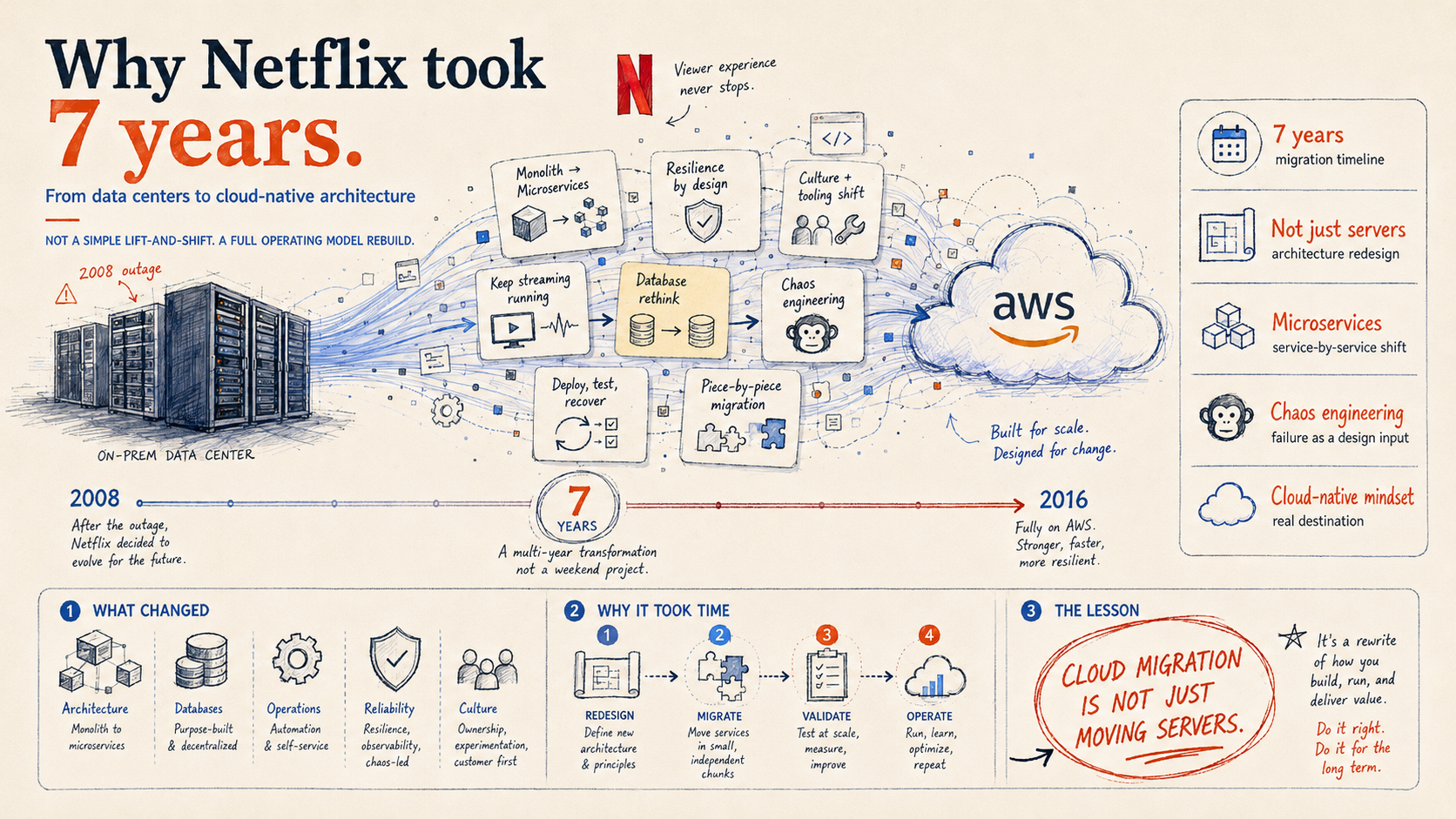
Netflix took 7 years to migrate to AWS.
That sounds slow until you understand what they were actually doing.
They were not just moving servers from one place to another. They were rebuilding the company's entire technology model while keeping Netflix running for millions of users.
That difference matters.
A cloud migration can be a hosting change. Netflix treated it as an architecture change, an operations change, a data change, and a culture change.
Quick Navigation
- Quick Navigation
- The Incident That Forced The Question
- Why Lift And Shift Was Not Enough
- The Hard Part Was Changing The Model
- Keeping The Business Running
- Failure Became Part Of The Design
- The Finish Line Was A Different Company
- What Other Teams Should Learn From It
The Incident That Forced The Question
The migration story started after a major database corruption in 2008.
At the time, Netflix was still heavily tied to its own data centers, relational databases, and vertically scaled systems. The incident caused a three-day disruption to DVD shipping and forced the company to rethink its infrastructure.
That is the kind of outage that changes the conversation.
Before a failure, infrastructure problems can sound theoretical. After a failure, they become business problems. Customers are affected. Teams are blocked. Leaders want to know what has to change so the same thing does not happen again.
Netflix could have responded with a smaller fix. Buy better hardware. Add more database redundancy. Improve backup procedures. Patch the immediate weakness.
Those things may have helped, but they would not have changed the deeper problem. Netflix was growing into a global streaming company. The old model was not going to be enough.
Why Lift And Shift Was Not Enough
The easy version of the migration would have been a lift and shift:
- Take the existing systems.
- Move them to Amazon Web Services.
- Call it cloud migration.
That approach can make sense for some companies. If the goal is to exit a data center quickly, reduce hardware ownership, or move a relatively stable workload, a lift and shift may be the practical first step.
But it does not automatically make a system cloud-native.
If you take a fragile architecture and move it into the cloud unchanged, you may simply get a fragile architecture with a different bill. The failure modes are still there. The deployment process is still there. The data model is still there. The operational habits are still there.
Netflix chose the harder path.
They rebuilt around cloud-native architecture.
That meant moving away from a monolithic application and toward hundreds of microservices. It meant redesigning data models, adopting NoSQL databases, changing operational practices, and building systems that expected failure instead of pretending failure would not happen.
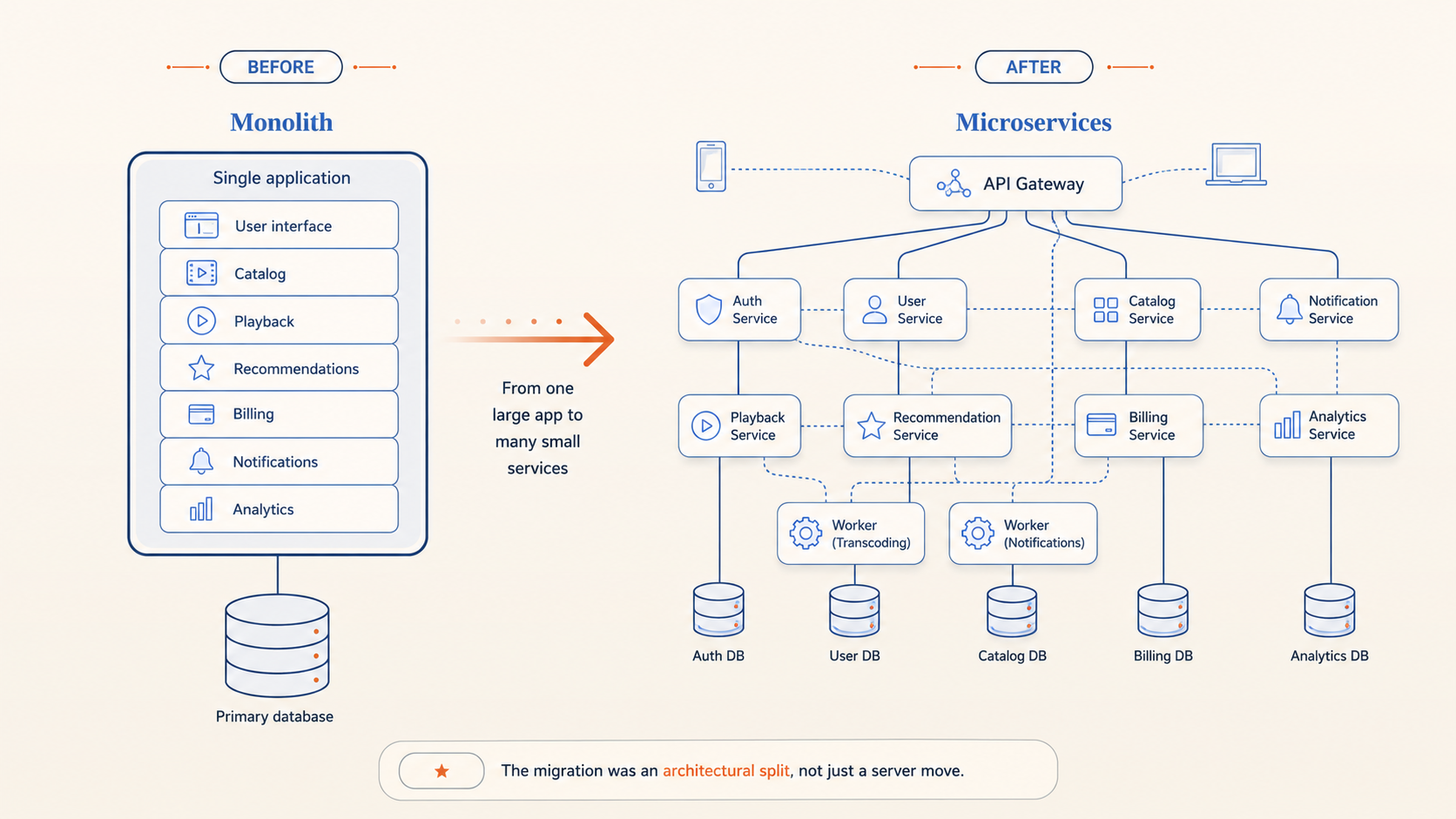
The bigger question was not where the code ran. It was how the whole system should behave.
The Hard Part Was Changing The Model
Big migrations do not take years because companies are moving bytes.
They take years because companies are changing how software is built.
Netflix had to rethink many parts of the stack at once:
- Application boundaries.
- Service ownership.
- Deployment pipelines.
- Data storage.
- Monitoring.
- Failure recovery.
- Capacity planning.
- Developer responsibility.
Each of those changes affects real teams.
A monolith can centralize complexity in one place. Microservices distribute that complexity across many services, teams, APIs, databases, and failure modes. That can be powerful, but only if the engineering organization is ready for it.
You need service discovery, observability, rollback strategies, sane deployment tooling, clear ownership, and engineers who understand production behavior.
The cloud gives you building blocks. It does not automatically give you a resilient system.
Netflix had to build the operating model around those building blocks.
Keeping The Business Running
The most impressive part of this migration is not that Netflix moved to AWS.
It is that they did it while Netflix kept running.
They could not pause streaming. They could not ask customers to come back in a few years. They could not accept a degraded experience just because the architecture was in transition.
That is what makes large migrations so difficult.
You are changing the engine while the product is moving.
Each piece has to be migrated, tested, monitored, and validated. Teams need confidence that the new system can handle real traffic. Rollbacks have to be possible. Dependencies have to be understood. A system that works in isolation can still fail when connected to everything else.
This is why "just migrate it" is rarely a serious plan.
The actual plan is usually a long sequence of smaller plans:
- Identify a bounded system.
- Understand its dependencies.
- Build the cloud-native replacement.
- Run it alongside the old system.
- Shift traffic carefully.
- Watch the metrics.
- Fix the unexpected behavior.
- Repeat.
The boring repetition is the migration.
Failure Became Part Of The Design
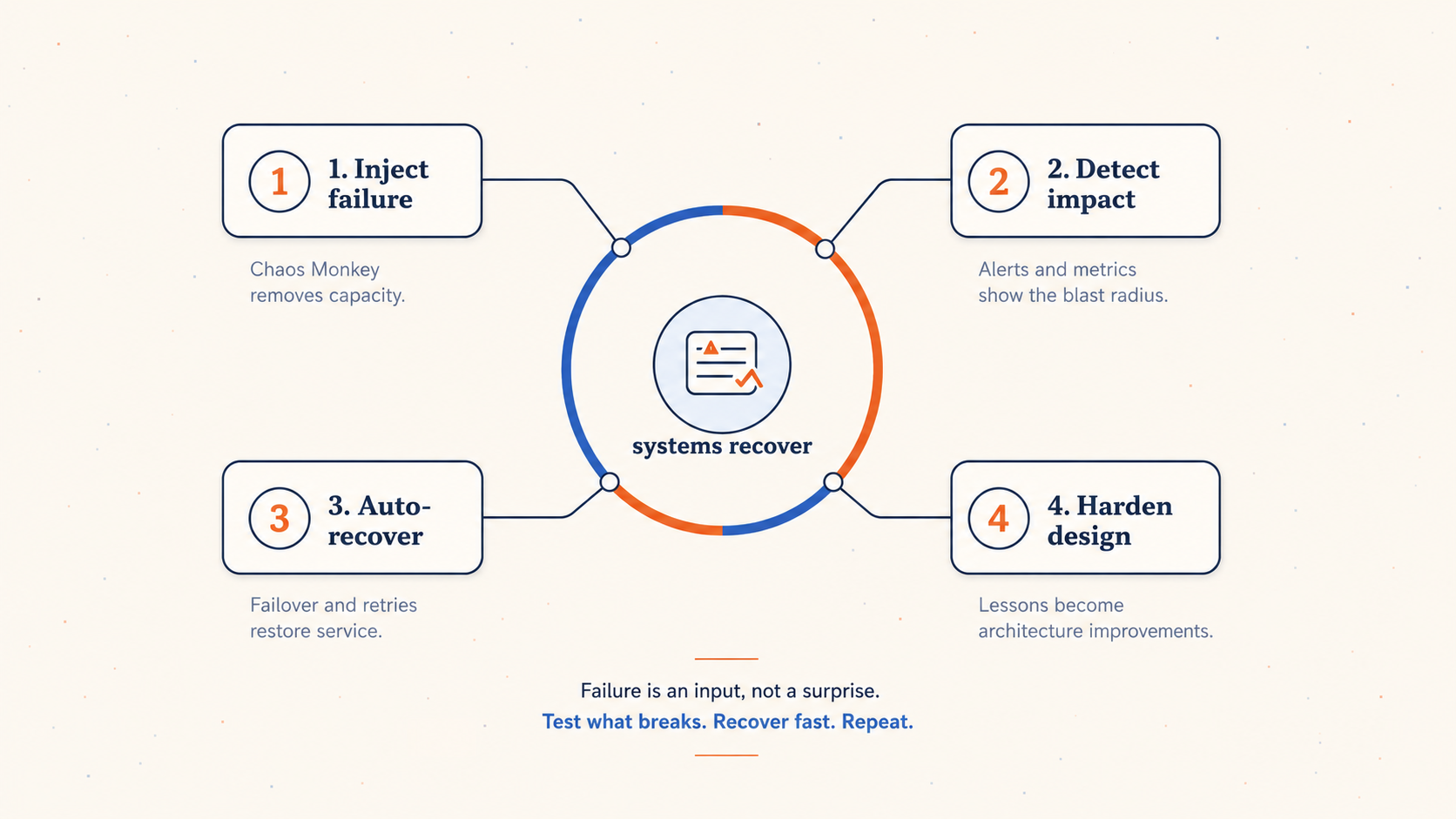
Netflix is also famous for chaos engineering, and that culture is closely tied to this migration.
Instead of hoping systems would survive failures, Netflix started testing failure directly. Tools like Chaos Monkey intentionally broke parts of production so engineers could build systems that recovered automatically.
That sounds extreme until you remember the goal.
In a distributed cloud system, things will fail.
Instances disappear. Networks behave strangely. Dependencies time out. Deployments introduce bugs. One service slows down and another service starts queueing requests. A regional issue becomes a customer experience issue.
The question Netflix team had wasn't whether failures happen, but rather whether the system expects and handles them correctly.
Chaos engineering turned failure from a surprise into a design input. It forced teams to ask practical questions:
- What happens if this instance dies?
- What happens if this dependency is slow?
- What happens if a service returns errors?
- What happens if a region has problems?
- What does the customer experience look like during partial failure?
That mindset is one of the real lessons of the Netflix migration.
Cloud-native architecture is not only about scaling up quickly. It is about degrading gracefully.
The Finish Line Was A Different Company
By early 2016, Netflix completed the migration and shut down the last remaining data center components used by its streaming service.
The finish line was bigger than "we are on AWS now."
Netflix had become a different kind of engineering organization.
They had moved from vertically scaled systems toward distributed systems. They had moved from data center assumptions toward cloud assumptions. They had moved from avoiding failure toward testing for failure. They had moved from large centralized systems toward smaller owned services.
That is why it took 7 years.
Not because copying data is slow.
Because changing the way a company builds software is slow.
What Other Teams Should Learn From It
The lesson is narrower than that: every company should not copy Netflix.
Most companies are not Netflix. They do not have Netflix's traffic, scale, budget, team structure, risk profile, or product constraints.
The lesson is more useful than that. Do not confuse cloud migration with cloud transformation.
If your goal is to reduce data center dependency, a lift and shift may be enough for the first phase.
If your goal is resilience, elasticity, faster delivery, global scale, and better recovery, then the architecture and operating model have to change too.
That means asking harder questions:
- Which systems should stay simple?
- Which systems actually need distributed architecture?
- Where does the current data model break down?
- What failure modes are hidden today?
- Who owns each service in production?
- How do we know when the migration is safer than the old system?
Smartest move might be a simple relocation. But the smarter move is a careful rebuild.
Netflix chose the rebuild because their future demanded it. That is why the migration took years. And that is why people still study it.